The human brain is a web of approximately 86 billion interconnected neurons, which collect electrical impulses of different weighted signals and send on a signal only once a sufficient bias charge has been reached.
Artificial versions of these networks were first developed in the 1940s, but it has only been in the last decade that computers have become powerful enough to simulate millions or billions of neurons. The networks are trained by optimising, over thousands of examples, the billions of weight and bias values so that particular inputs always map through the network to chosen learnt outputs. Much of the heavy work of training for computer vision problems can be short-cut by transferring learning using large general-purpose models such as ResNet 18 that have already been trained on millions of images.
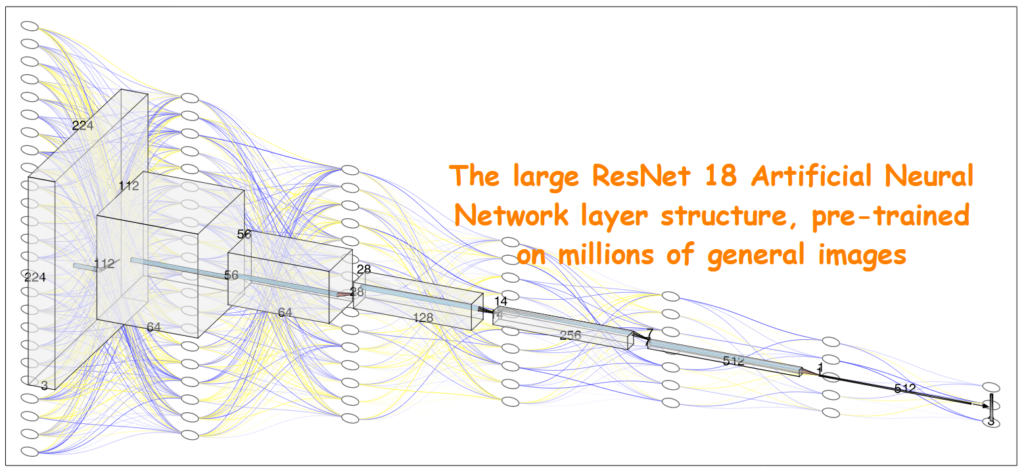
The final layer of the model is trained by in a process called back-propagation. Given an error between a prediction of a result and the true result, this method calculates the difference between the two, and the direction of change needed in the neural network’s weights and biases to make the difference smaller. The “backwards” part of the name stems from the fact that calculation of the gradient proceeds backwards through the network, with the gradient of the final layer of weights being calculated first and the gradient of the first layer of weights being calculated last.
Grant Sanderson, of 3blue1brown, has created an excellent, readily understandable, series on Artificial Neural Networks and the process of training them [ ↵ ].
There are several large Neural Network models included in NVIDIA Jetpack SDK which have all been pre-trained on millions of general images to develop general understanding of what a camera is looking at. We begin with ResNet 18 because it is the smallest, which is useful for a system with only 2GB of memory.
A discussion of some of the different models available is made in the detailed walkthrough video of the 03 Investigating the Code guide,
the written detailed guide to the Python code used can be downloaded here,
03 Investigation of the Code_Guide [ ⇓ ]
The code itself is available in the project github repository [ ↵ ].
Through transfer-learning, these pre-trained models are used as the starting point from which new training is performed – to specialise the recognition to a few specific items. This permits successful models to be built using fewer training images than would be required if trying to learn a situation from scratch.
Quick Shortcuts to project resources:
a glossary of the highlighted technical terms used can be downloaded here [ ⇓ ]
download the eBooklet [ ⇓ ], a digital copy of the printed project booklet
Share this post
![]()
![]()